浏览器加载页面的顺序
浏览器加载html页面各家不一样,但有一些主流行为。
1. 浏览器是从上而下解析html,边解析边渲染,遇到外链文件比如css或者js就堵塞解析,下载外链文件,并开始执行这些文件,执行过程中不段重绘已经渲染但需要调整的DOM元素,基于这种原因,一般建议将css文件链接在html的头部,而将js置于html的尾部,这样减少重绘同时又让页面能更快地展现出内容来。
2. 图片即<img>标签没有指定宽高时,就先跳过,当图片被异步下载下来并确定了宽高之后,会重绘页面,当这样的图片多了,此时页面会各种重排而闪烁。如果预告指定好了宽高,空间会提前预留,从而大大减少重绘。
3. 浏览器在异步下载图片时,单个域名线程数会控制在一定范围内,所以对于大量图片需要加载的商城站,多使用多个域名来拼接图片的URL路径。
4. 浏览器会将所有的外链文件下载到本地,哪怕有某个js或者css根本没有被用到。
5. 多个js文件之间有时有依赖,有时没有,有时会操作DOM有时,有的不会,有的加载完成就被使用,有的则并不是,所以就有了async和defer来修饰,一图胜言:

注意:async并不能保证js脚本执行的次序就是在代码被引用的先后次序
6. 浏览器渲染工作步骤大概为:
- 处理 HTML 标记,构建 DOM 树。
- 处理 CSS 标记,构建 CSSOM 树。
- 将 DOM 树和 CSSOM 树融合成渲染树。
- 根据渲染树来布局,计算每个节点的几何信息。
- 在屏幕上绘制各个节点。
两棵树的融合过程如图:
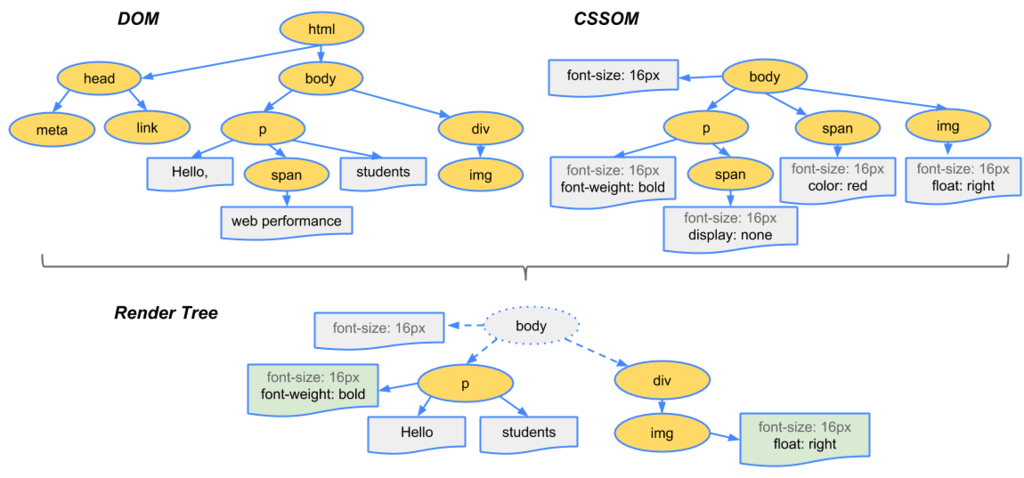
7. visibility: hidden 与 display: none 是不一样的。前者隐藏元素,但该元素在布局中仍占据空间(即被渲染成一个空盒子),而后者 (display: none) 是直接从渲染树中整个地移除元素,该元素既不可见,也不属于布局。
8. 浏览器在解析到一个<script>标签时,它不知道这个脚本会改变DOM树里的什么,或者是改变CSSOM树里的什么,因为脚本的自由度太巨大,于是将暂停解析页面,将控制权移交给javascript引擎,等待脚本执行完(如果是远程,还得先下载),然后再继续进行html页面的解析。所以js是不能操作在它之后出现的DOM元素的,js如果彼此之间有依赖,也应该按依赖次序书写。接着javascript的执行又会被css所堵塞,因为无法预测js是否会操作CSSOM,所以会先下载并构建好整个CSSOM树,才会开始js的执行。当然浏览器不会傻等着,各种css和js的下载几乎是并行的,而网络耗时是绝对大头,所以整体来看,基本还是两次网络往返的耗时。

9. 在所有的资源下载完成,包括图片资源,并完成渲染,浏览器会触发onLoad事件。